- 完全托管、高度可用,可跨多个可用区进行复制
- NoSQL 数据库 - 不是关系数据库 - 具有事务支持 • 可扩展到海量工作负载、分布式数据库
- 每秒数百万个请求、数万亿行、数百TB 存储 • 快速且一致的性能(个位数毫秒)
- 与 IAM 集成以实现安全、授权和管理
- 低成本和自动扩展功能
- 无需维护或修补,始终可用
- 标准和不频繁访问 (IA) 表类
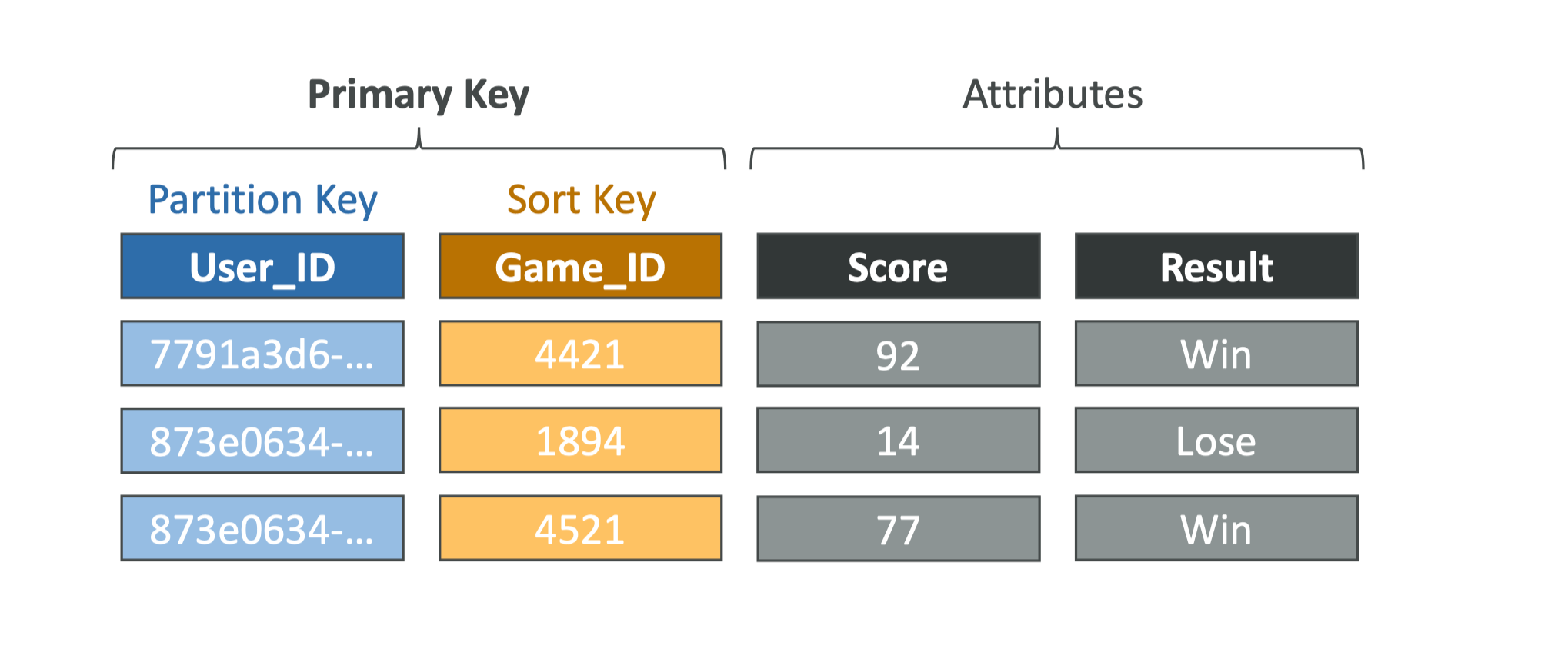
每个表都有一个主键,主键可以只有一个分区键,也可以分区键和排序键单个item最大400K
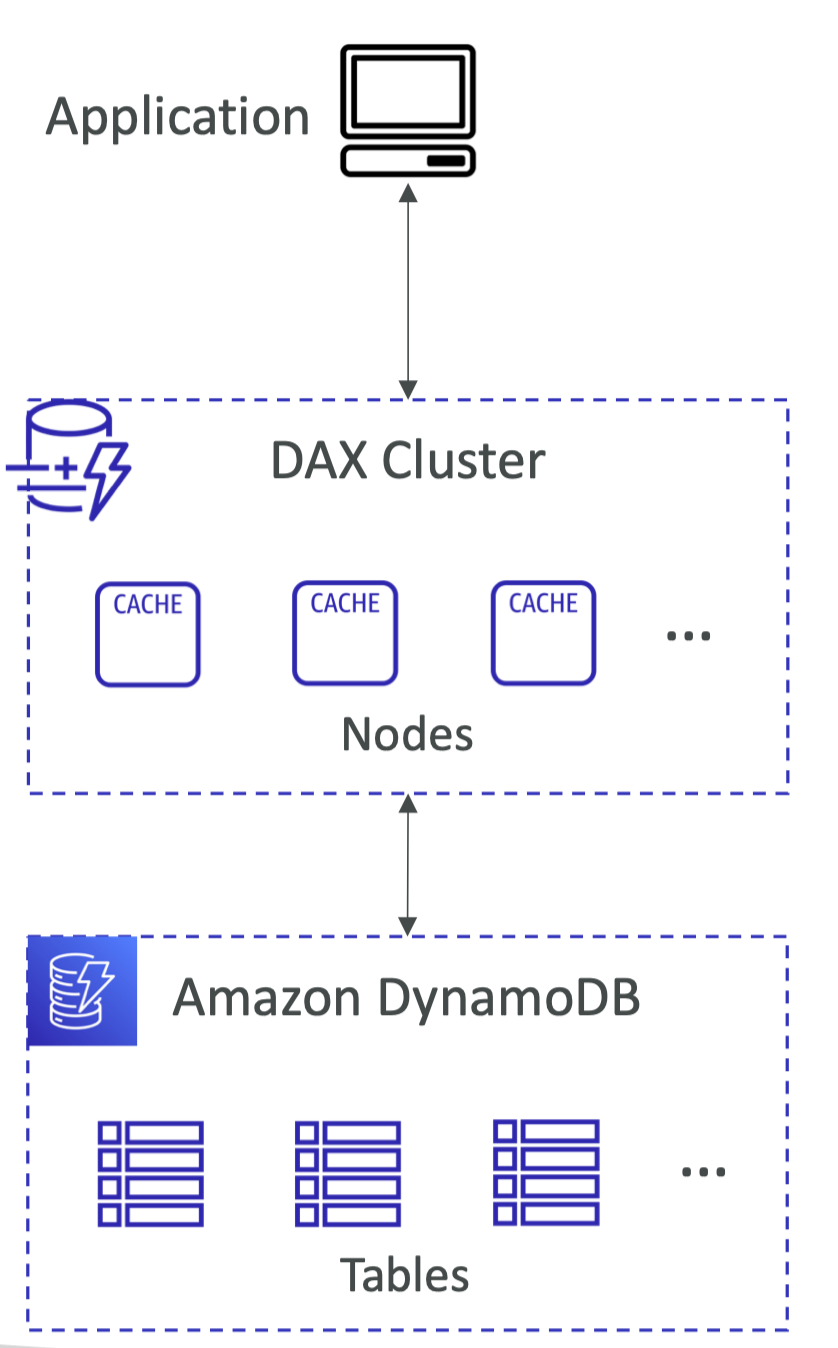
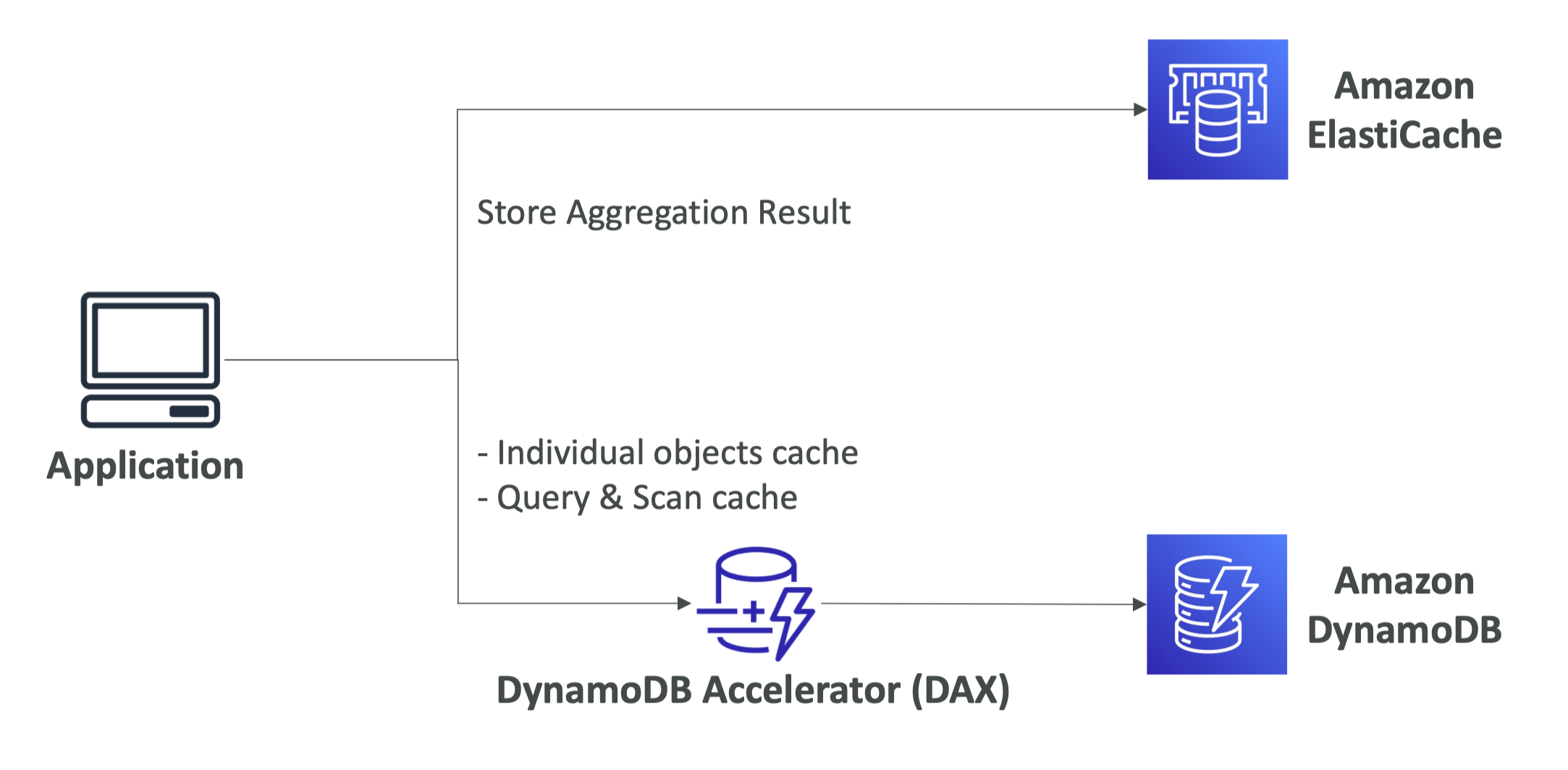
缓存
DAX做缓存,5分钟的TTL,不需要额外更改API,毫秒级别延迟
和redis的对比
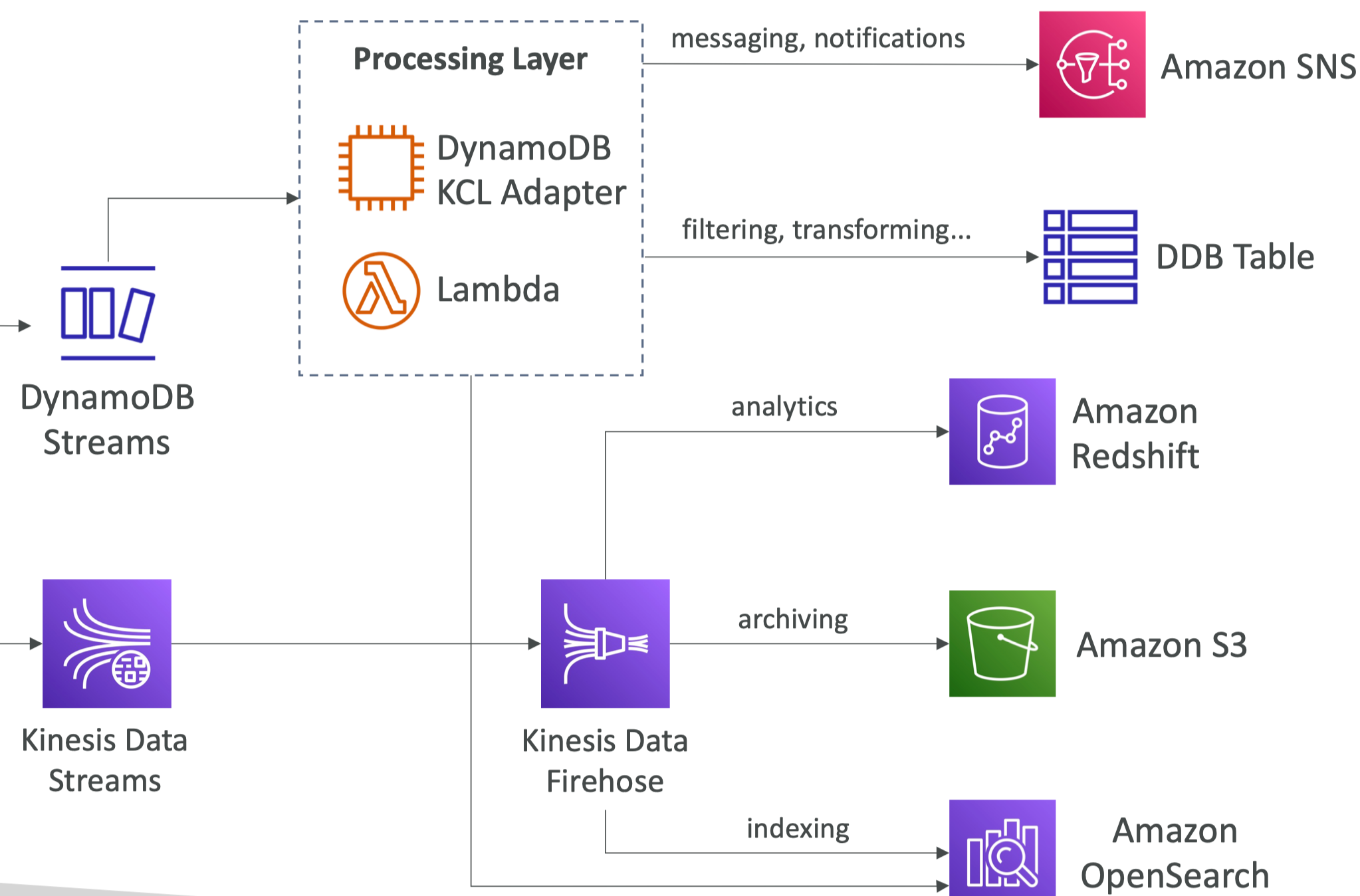
ddb stream
DynamoDB – 流处理
• 表中项目级修改(创建/更新/删除)的有序流 • 用例:
• 实时响应变化(向用户发送欢迎电子邮件)
• 实时使用情况分析
• 插入衍生表
• 实施跨区域复制
• 对 DynamoDB 表的更改调用 AWS Lambda

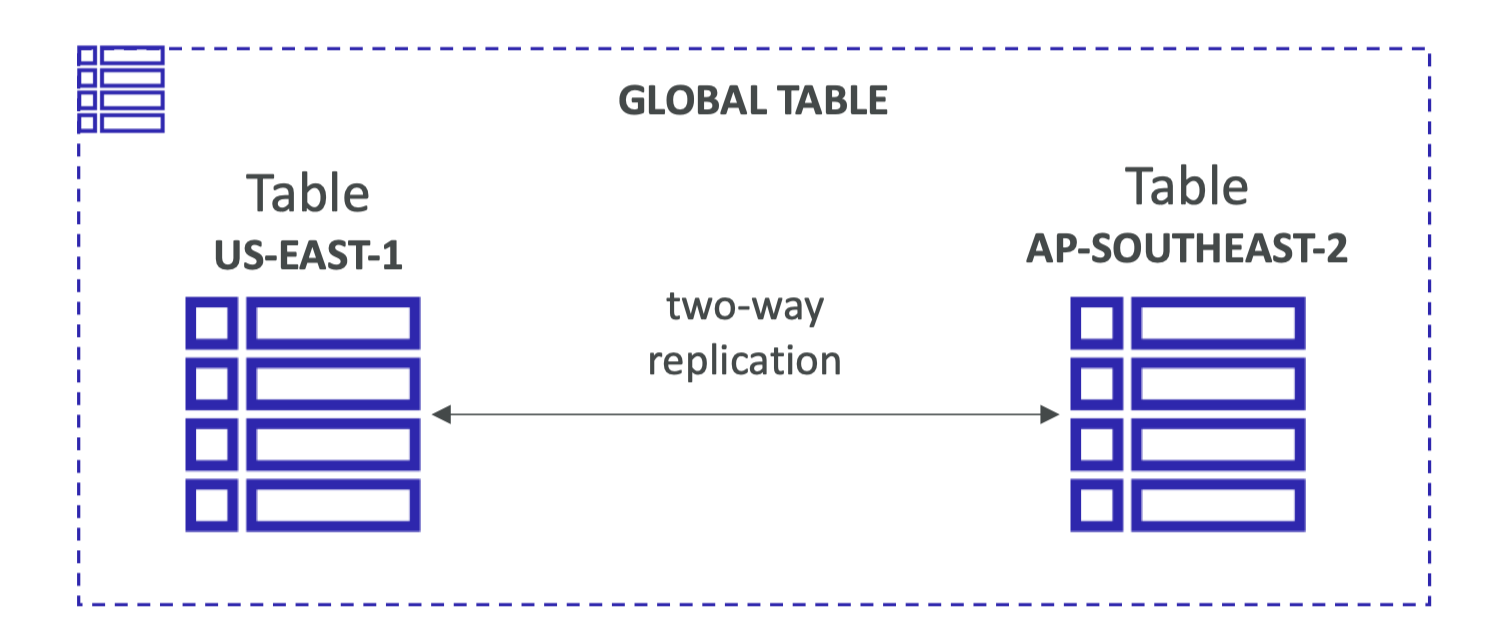
DDB的全局表
- Make a DynamoDB table accessible with low latency in multiple-regions
- Active-Active replication
- Applications can READand WRITEto the table in any region
- Must enable DynamoDB Streams as a pre-requisite
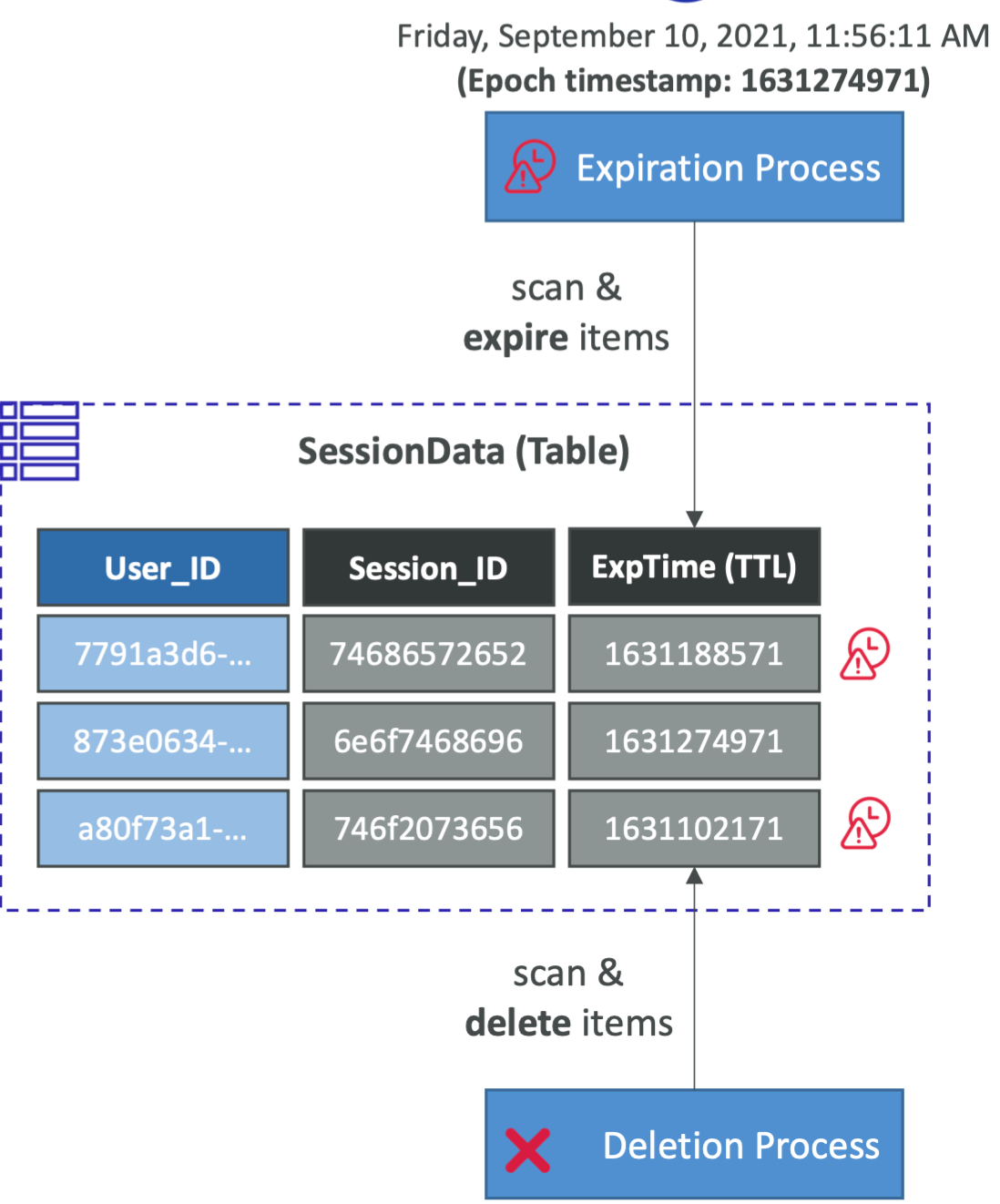
DDB的TTL
- 在过期时间戳后自动删除项目
- 使用案例:通过仅保留当前项目来减少存储的数据,遵守法规义务、网络会话处理……
DynamoDB – 用于灾难恢复的备份
使用时间点恢复 (PITR) 进行连续备份
- 可选择在过去 35 天内启用
- 时间点恢复到备份窗口内的任何时间
- 恢复过程创建一个新表
按需备份
- 完整备份可长期保留,直至明确删除
- 不影响性能或延迟
- 可以在AWS Backup 中进行配置和管理(启用跨区域复制) • 恢复过程会创建一个新表
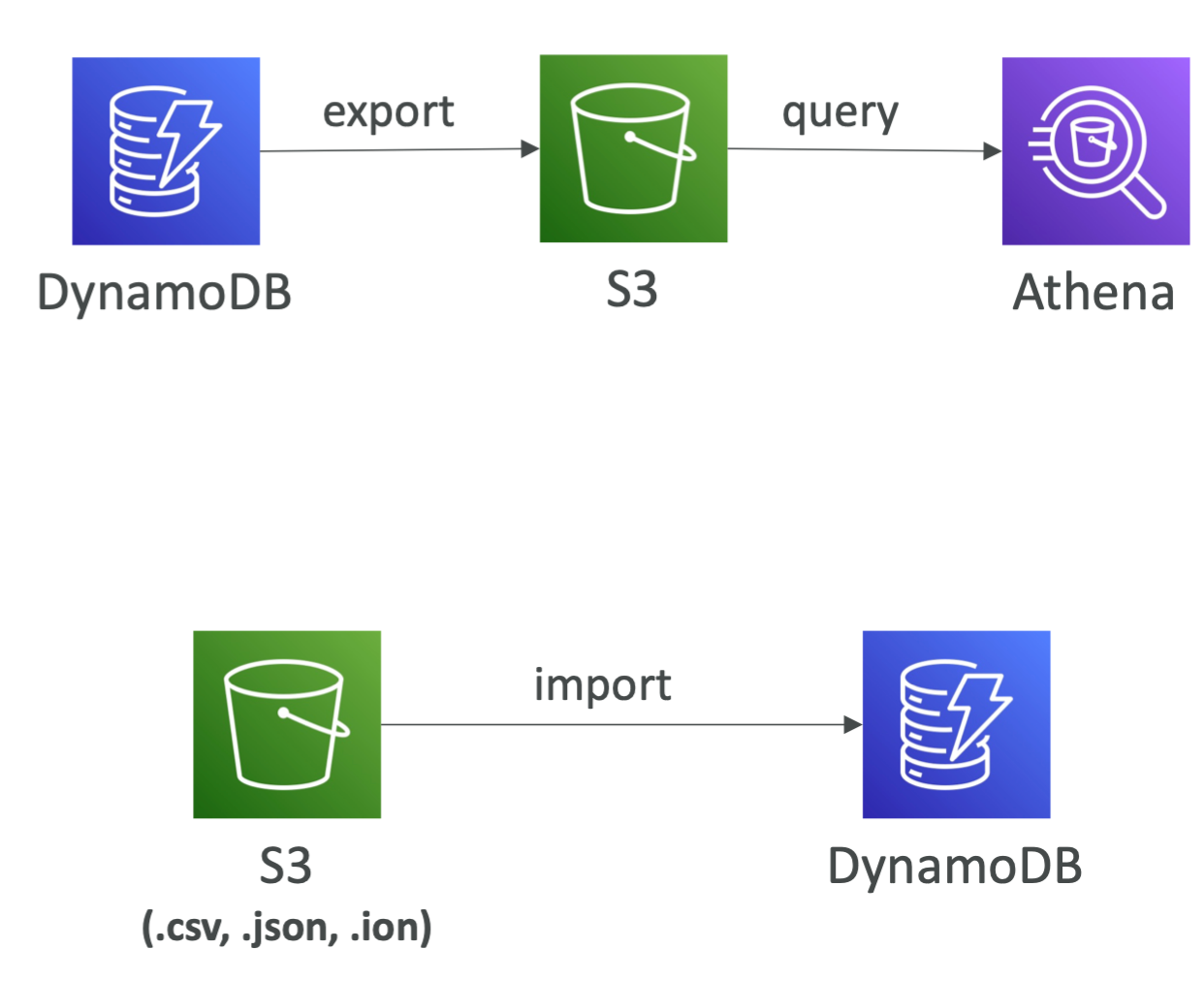
DynamoDB – 与 Amazon S3 集成
导出到S3(必须启用PITR)
- 适用于过去 35 天内的任何时间点
- 不影响表的读取容量
- 在DynamoDB 之上执行数据分析
- 保留快照以供审核
- 在导入回 DynamoDB 之前对 S3 数据进行 ETL
- 以DynamoDB JSON 或ION 格式导出
从S3 导入
- 导入 CSV、DynamoDB JSON 或 ION 格式
- 不消耗任何写入容量
- 创建一个新表
- 导入错误记录在CloudWatch Logs 中